Разбивка озвученного аудио на фрагменты в Звукограм
18 сентября 2025 , Обновлено
18 сентября 2025
Звукограм создает из текста цельный аудиофайл в форматах MP3, WAV и OGG. Но для монтажа роликов или подкастов часто нужны отдельные фрагменты — система умеет автоматически разрезать озвученный текст на куски.
Как разбить аудио на отрезки
Поставьте курсор в нужное место и нажмите кнопку разделения в панели меню:
Кнопка вставляет специальный тег <obrezka/>. Можете копировать его и расставлять по тексту вручную — где поставите тег, там аудио и разрежется.
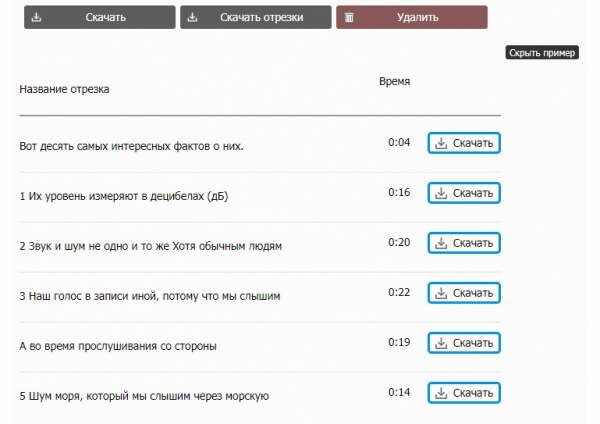
После добавления хотя бы одного тега в озвученном файле появится кнопка "скачать отрезки":
Нажмите — все фрагменты начнут скачиваться на компьютер или телефон одной очередью.
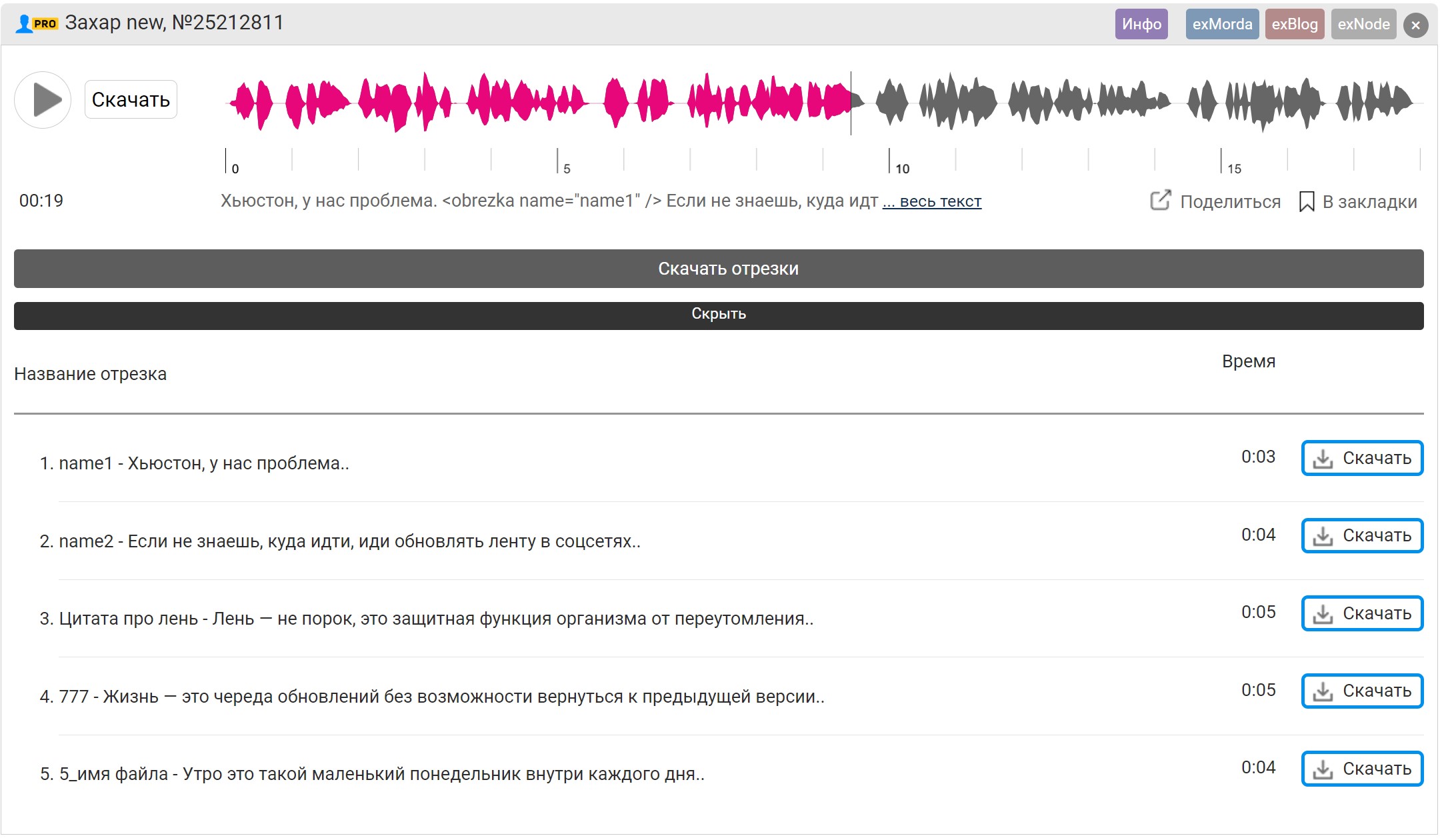
Чтобы загрузить конкретный отрезок, разверните список кнопкой "подробнее" под аудиодорожкой:
Здесь показаны все фрагменты по порядку с длительностью и названиями. Система берет первые слова из каждого куска — так легко понять, какой файл за что отвечает.
Скачанные файлы получают осмысленные имена. Например:
4787626_5_a-vo-vremya-proslushivan
4787626 — уникальный номер озвучки (одинаковый для всех отрезков) 5 — порядковый номер фрагмента a-vo-vremya-proslushivan — название из первых слов отрезка
Собственные имена файлов
Можете задать любые названия для отрезков. Добавьте параметр name в тег и система присвоит файлу это имя:
<obrezka name="название_файла" />
Используйте кириллицу, латиницу, цифры, пробелы — что угодно:
После озвучки в интерфейсе увидите заданное имя и через дефис — начало текста отрезка:
Если имя не указано, Звукограм сгенерирует его автоматически из первых слов.
Хотите просто переименовать весь файл? Поставьте один тег <obrezka name="мое_название" /> в конце текста — получите единый файл с нужным именем.
Ограничения на количество отрезков
Рекомендуемый лимит: до 1000 коротких отрезков или 500 длинных за одну озвучку. Если появились пустые файлы — превысили лимит, разбейте текст на несколько отдельных озвучек.